В наших предыдущих статьях мы уже рассказывали о таком полезном инструменте как grep. С помощью данной утилиты пользователь легко может отфильтровать из вывода нужную информацию. И существенно упростить себе жизнь при работе с большими файлами. Или же с программами, выдающими огромные массивы информации. Сегодня мы расскажем о том, как при работе с grep брать шаблоны из файла — это входит в операционная система Linux курс лекций Варшава.
Как создать файл с шаблонами для команды grep, операционная система Linux курс лекций Варшава
Прежде всего остального, давайте разберемся, для чего вам может понадобиться файл с шаблонами для grep. Это вполне логичное решение, если вы регулярно выполняете одни и те же операции. Стоит отметить, что именно в этом и состоит работа системного администратора. Примерно 90% повторений рутинных задач и 10% экстремального устранения непредвиденных сбоев. Чтобы узнать больше — советуем пройти безопасность Linux курс Варшава на платформе SEDICOMM University.
Теперь перейдем к инструментам для создания такого файла шаблонов. Для этого вы можете воспользоваться одним из следующих решений:
- перенаправление стандартного вывода (поток 1);
- использование текстовых редакторов (nano или vim).
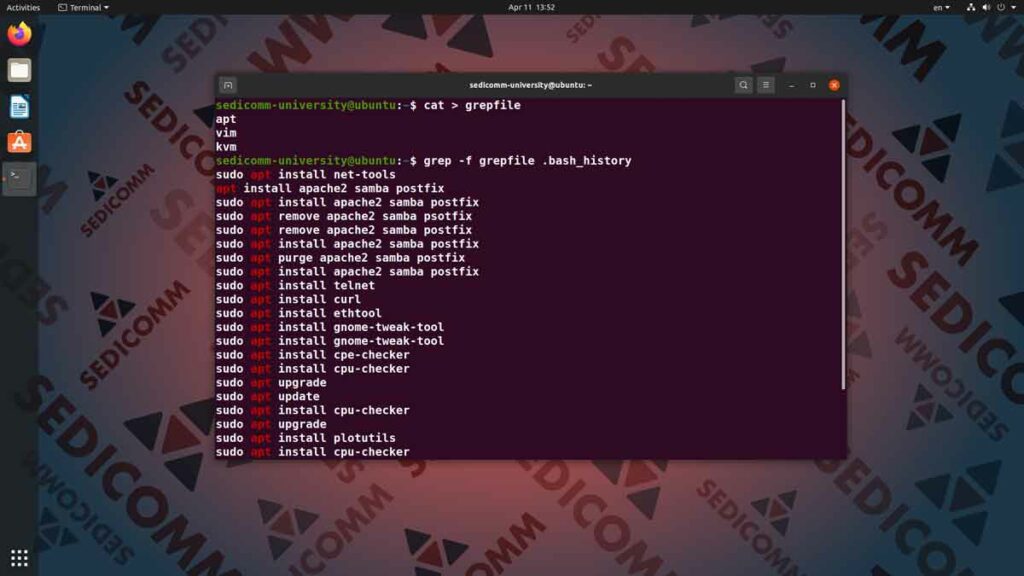
Начнем с первого варианта — перенаправления текстового потока стандартного вывода. Для этого вводим в командную строку команду cat, ставим после нее символ «больше» («>») и пишем название файла (например — templates_file). После этого нажимаем клавишу Enter для выполнения команды. В результате командная оболочка предложит вам ввести текст с клавиатуры. Помните, что одна строка — один шаблон grep. Для завершения введения текста достаточно нажать комбинацию клавиш Ctrl + D.
Стоит отметить, что одиночный символ «больше» — «>» — всегда перезаписывает содержимое файла. Следовательно, используйте его осторожно, чтобы не удалить из ранее существующего файла полезные данные. Чтобы добавить новые шаблоны к существующему файлу — используйте двойной символ «больше» («>>»). От предыдущего примера он отличается тем, что добавляет новые строки в конце файла, если тот уже существует.
Безусловно, при работе с файлами, содержащими большое количество шаблонов, проще использовать текстовые редакторы. Для этого введите в командную строку команду vim templates_file (или nano templates_file). Детальнее о том, как использовать такие программы — мы уже писали в наших предыдущих статьях. Если вы желаете освоить работу с текстовыми редакторами командной строки — приглашаем вас на курсы Linux torrent Варшава. Которые можно пройти в онлайн-формате на платформе SEDICOMM University.
Как использовать для фильтрации вывода с помощью команды grep шаблоны из файла
Допустим, что у вас есть файл sample_file с большим количеством текста. И вас интересуют лишь отдельные строки, содержащие шаблоны из заранее заготовленного файла templates_file. Давайте попробуем с помощью команды grep отфильтровать и вывести на экран строки, соответствующие искомым шаблонам из нашего файла. Советуем пройти Linux online курсы Варшава, чтобы освоить командную строку Линукс в совершенстве.
Итак, вводим в командную строку команду grep, далее добавляем опцию -f и название файла с шаблонами в качестве первого аргумента— templates_file. Либо, добавляем опцию аргумент вместе — —file=templates_file. Далее ставим пробел и добавляем в качестве второго аргумента название файла, по которому будет выполняться поиск. После нажатия клавиши Enter на экран будут выведены все строки, совпадающие с шаблонами.
Допустим, что вас интересуют строки, не совпадающие с искомыми шаблонами (то есть, совпадения нужно исключить). В таком случае — просто добавьте к примеру, приведенному выше, опцию -v. Если же вас интересуют лишь точные совпадения (когда искомый шаблон и слово идентичны) — замените опцию -v на опцию -w. А если такое слово должно быть отдельной строкой — на опцию -x.
Команда SEDICOMM University: Академия Cisco, Linux Professional Institute, Python Institute.